
Top 5 Java Big Data Frameworks To Learn & Leverage In 2022
Big data is one of the hottest topics in the tech world today, but what if you’re just a Java developer who wants to help out? Even if you’re not doing big data work yourself, you need to be familiar with the landscape in order to make an informed decision when someone asks you which framework they should use.
In this article, we’ll cover five of the most popular Java frameworks used for Big Data. Each of these frameworks offers a unique set of functionalities and knowing what they do is crucial if you’re looking to work in this field. So, keep reading!
Top Java Big Data Frameworks You Shouldn’t Miss Out On
- Hadoop
Apache Hadoop is one of the very popular Java Big Data frameworks for distributed processing of large data sets. It’s most commonly used for storing and processing huge amounts of unstructured data in distributed clusters. But! it can also be leveraged for batch processing or interactive queries on smaller data sets.
Hadoop uses what is called MapReduce jobs—essentially scripts that determine how your data will be processed across your cluster—to execute. These map tasks break up the input data into manageable chunks and produce key-value pairs as outputs.
Then, these reduced tasks take the key-value pairs produced by the map tasks and combine them into a single value. These two steps allow parallelization of all computing operations because each job runs on different parts of the input dataset simultaneously.
MapReduce jobs can be written in several programming languages (including Java) which means developers have more control over the process. If you need high-volume storage and/or processing with minimal downtime then this may be a good option for you.
#2. Apache Spark
Apache Spark is a fast and general-purpose big data processing engine. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general execution graphs. Spark was developed in response to limitations in contemporary systems such as Hadoop MapReduce.
In simple terms, Spark allows users to run programs where it works best: in-memory, on disks, or distributed across any environment—making it more versatile than MapReduce. Spark also simplifies the process of finding meaning from vast amounts of unstructured information.
It can rapidly analyze large datasets without needing pre-sorting and with less demand for disk storage space. Furthermore, the use of interactive queries makes it easier to explore data interactively at the same time as performing batch jobs.
Here is how Spark works:
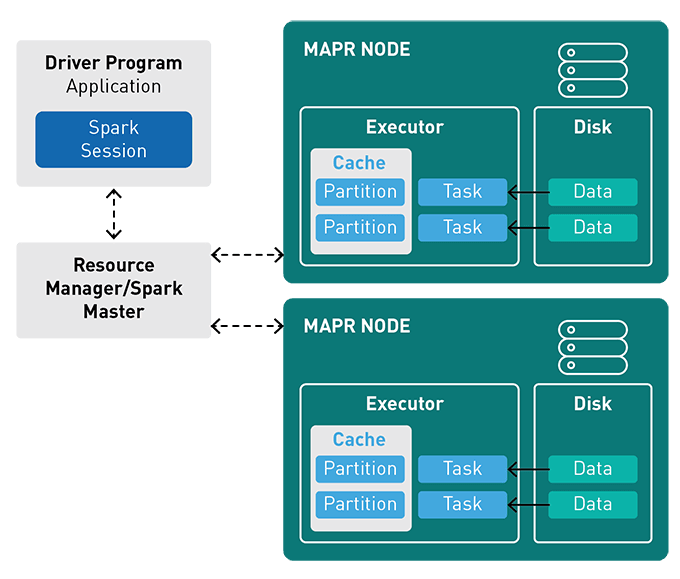
Most importantly, Spark’s speed combined with its rich set of tools makes it one of the most efficient frameworks available today. Apache Spark is a major preference of almost every Java development company in India due to its immense capabilities.
So, if you want to create an advanced solution with a Big Data capability, you should pick this Java Big Data framework now!
Here Is How does Spark work
#3. Apache Drill
Drill is a next-generation, open-source SQL query engine for Hadoop. It enables users to run SQL queries against large datasets residing in HDFS and Apache HBase without requiring data movement or transformation.
Its architecture was designed with input from the leading database and Hadoop experts. It is the only SQL query engine that can execute natively within Hadoop’s map/reduce framework, running queries in parallel across any number of nodes.
Users can also use Drill to explore near real-time operational data on HBase tables using traditional SQL language statements. It is available as an interactive shell (Drill Shell), an API for advanced developers, or as a standalone command-line tool.
The latest release includes many new features including union support, project functions, and windowing functions. All of these aspects make it one of the top Java Big Data frameworks with cutting-edge features.
If you hire Java developers with Apache Drill know-how, you can create the most incredible solutions with ease.
#4. Flink
Apache Flink is an open-source stream and batch data processing framework written in Java. It can handle both standalone and distributed computing. Apache Flink has been designed with a strong focus on performance, stability, and ease of use.
Most importantly, it’s highly scalable across single machines as well as multiple machines. Developers can deploy Apache Flink applications either by using the provided IDE or from the command line.
The key feature of Flink is its pluggable architecture which enables it to support various data sources and backends. A simple implementation for Apache Kafka (incubating) is included as part of Flink 0.9.2 as well as connectors for HDFS, HBase, and MongoDB.
Apache Flink Architecture:
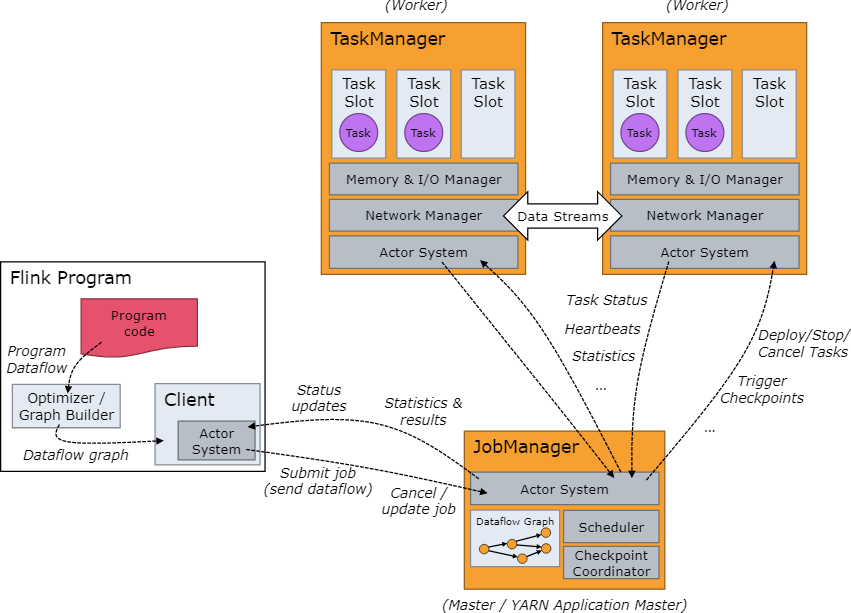
Flink’s main modules are:
Apache Spark: Spark is a fast, general-purpose cluster computing system with strong language integration features including SQL, Scala, Python, and R.
Mahout: Research and provides scalable implementations of common clustering and classification algorithms. These include k-means clustering, naive Bayes classification, decision trees, random forests, Gaussian mixture models, and more.
TensorFlow: TensorFlow is an open-source software library for numerical computation using data flow graphs. The graphs represent mathematical operations, where nodes represent mathematical operations on real numbers or vectors and edges represent input values that feed into those operations.
It is a one-stop solution for developers looking for Java Big Data frameworks & solutions to implement complex analytical capacity to system software.
#5. Kafka
Kafka is a distributed and partitioned commit log service that lets you publish and subscribe to streams of records (called events). It’s one of several open-source technologies in a category called messaging-oriented middleware (MOM).
While Kafka can be used as a simple message broker, it’s generally used as part of complex systems. As an example, LinkedIn uses Kafka at its core. So does Netflix, which has a lot of interest in reducing outages.
The framework can handle high volumes of messages with very low latency rates because it spreads the load across a cluster and stores everything on a disk. All that said, Kafka isn’t the simplest Java Big data framework to use if your goal is simplicity; there are easier options out there for those who just want to get started quickly.
Wrapping up
The Java Big Data frameworks mentioned are reliable and industry-best. Also, large community support makes them easy to use and advanced. If you want to create a solution with Big Data capabilities, you must hire Java developers in India with comprehensive skills in any of these frameworks.
Thanks for taking a moment to check out our top java big data frameworks. We decided on five due to how much content we were working with. If you think there are other frameworks out there, we encourage you to reach out and let us know about them.
FAQs:
Does Java play a role in big data?
Yes. Big Data has many tools that can use Java programming language, including Hadoop (which is programmed completely in Java). Learning how to use some of these Big Data Tools feels similar to learning how to use new APIs within the Java programming language.
Why do data engineers require Java skills?
Java tools for big data (Hadoop, Spark, Mahout) tend to be open-source and offer greater flexibility. As a result, those seeking out data engineer positions will look at both the worker’s skill in Java programming as well as their understanding of how to work with these types of software.
Do data analysts use Java?
To some extent, yes! But for data scientists, Java provides a slew of data science functionalities such as data analysis, processing raw datasets, statistical analysis (also known as exploratory statistics), visualizing visualizations (i.e., plotting graphs), and natural language parsing.
Java is also helpful when applying machine learning algorithms to real-world applications or problem-solving scenarios.
Java India offers high-quality Java Development services to clients with diverse requirements and from various industry verticals. We bring together the expertise and experience of seasoned Java developers to create applications that deliver excellent results for the client's business.